搜索资源平台推荐站长添加主站(您网站的链接也许会使用www 和非 www 两种网址,建议添加用户能够真实访问到的网址),添加并验证后,可证明您是该域名的拥有者,可以快捷批量添加子站点,查看所有子站数据,无需再一一验证您的子站点。
百度搜索资源平台提供三种验证方式(百度统计的导入方式已下线):文件验证、html标签验证、CNAME验证。
1.文件验证:您需要下载验证文件,将文件上传至您的服务器,放置于域名根目录下。
2.html标签验证:将html标签添加至网站首页html代码的<head>标签与</head>标签之间。
3.CNAME验证:您需要登录域名提供商或托管服务提供商的网站,添加新的DNS记录。
验证完成后,我们将会认为您是网站的拥有者。为使您的网站一直保持验证通过的状态,请保留验证的文件、html标签或CNAME记录,我们会去定期检查验证记录。
常见错误 | 推荐解决办法 |
无法解析您网站的域名 | 请检查网站的DNS设置是否正确,并更新您网站自己的DNS |
无法连接到您网站的服务器 | 请检查网站服务器设置是否正确,是否可正常访问 |
获取验证文件或网页发生错误 | 请检查服务器设置,或者稍后重试 |
您网站跳转次数过多 | 请检查服务器设置,是否设置了多次跳转,如果设置了多次跳转,请取消跳转后重新尝试验证您的网站 |
服务器检查结果为空 | 请检查服务器是否对百度做了特殊的设置(例如:对百度进行了封禁),或者稍后重试 |
我们无法访问您的网站 | 请检查服务器设置是否正确,可能是您的网站是否对百度做了UA/IP封禁,如果做了封禁请解除封禁后重新尝试验证您的网站 |
找不到验证的html标签或者验证的html标签内容错误 | 请检查html标签内容是否正确 |
验证的文件内容错误 | 请检查html标签内容是否正确 |
没有找到对应的DNS CNAME记录 | 请检查您网站的DNS设置是否正确 |
您的网站跳转到另一个域名下 | 请检查服务器是否设置了跳转,如果设置了请去掉跳转后重新尝试验证您的网站 |
点击查看站点验证图文详解
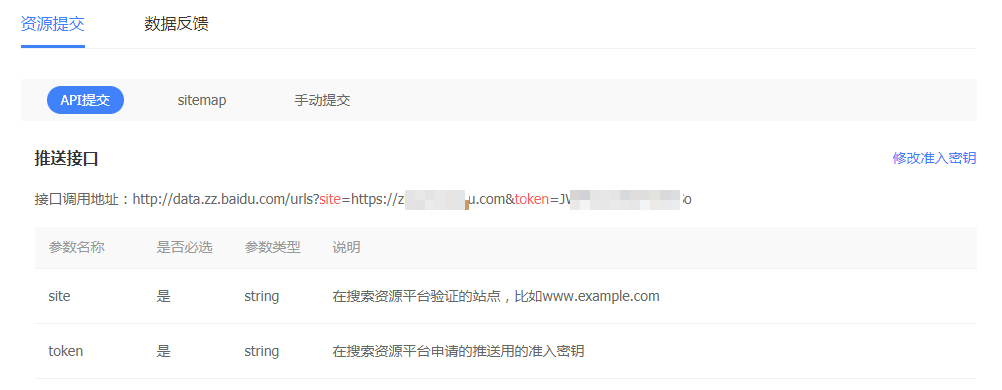
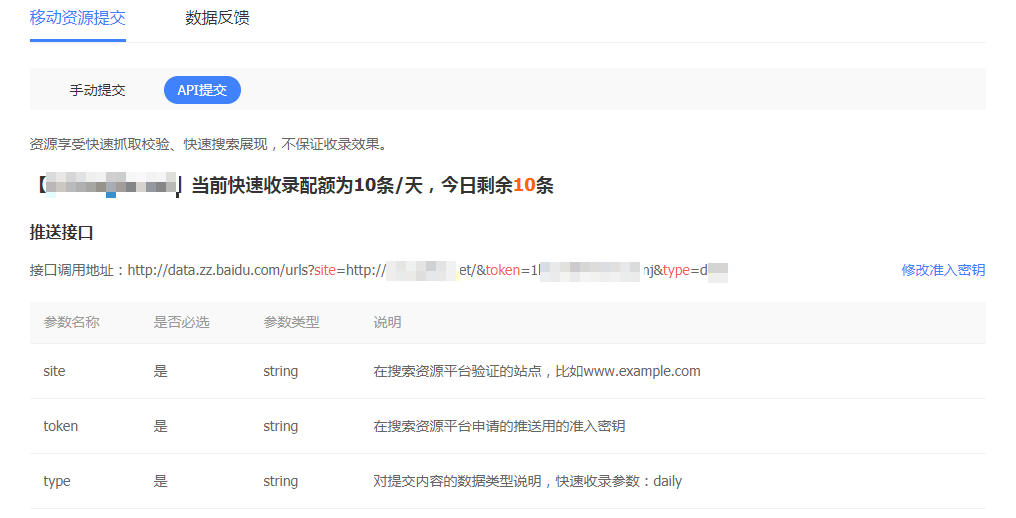
API推送:最为快速的提交方式,建议您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录。
sitemap:您可以定期将网站链接放到Sitemap中,然后将Sitemap提交给百度。百度会周期性的抓取检查您提交的Sitemap,对其中的链接进行处理,但收录速度慢于API推送。
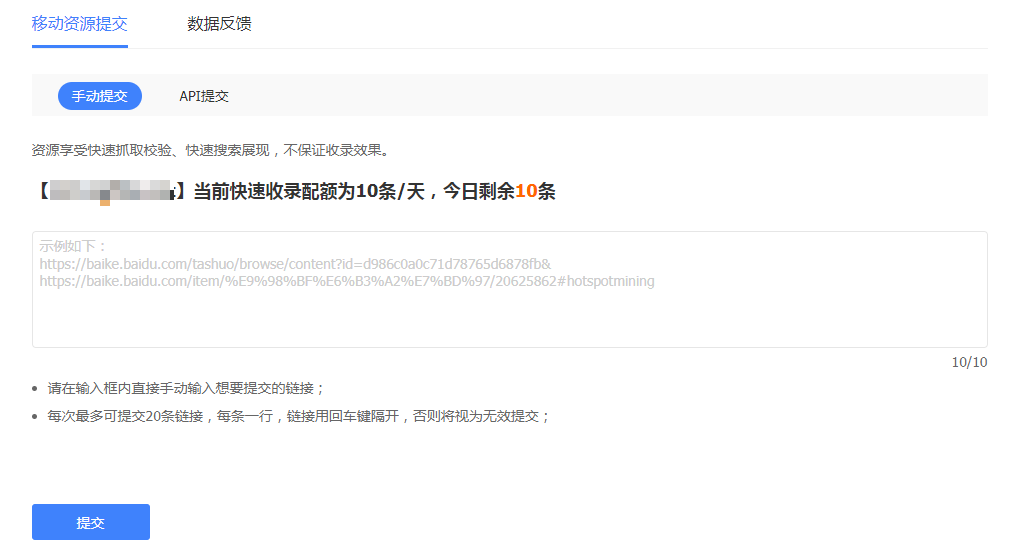
手动提交:如果您不想通过程序提交,那么可以采用此种方式,手动将链接提交给百度。
自动推送:轻量级链接提交组件,将自动推送的JS代码放置在站点每一个页面源代码中,当页面被访问时,页面链接会自动推送给百度,有利于新页面更快被百度发现。
及时发现:可以缩短百度爬虫发现您站点新链接的时间,使新发布的页面可以在第一时间被百度收录
保护原创:对于网站的最新原创内容,使用API推送功能可以快速通知到百度,使内容可以在转发之前被百度发现
1,需要网站制作数据推送接口,进入API推送工具后,会看到接口调用地址的token,token是由16个英文数字组合的字符串
您可以通过推送后返回的状态码和字段来判断数据是否推送成功。
1,状态码为200,表示推送成功,可能返回以下字段:
字段
是否必选
参数类型
说明
success
是
int
成功推送的url条数
remain
是
int
当天剩余的可推送url条数
not_same_site
否
array
由于不是本站url而未处理的url列表
not_valid
否
array
不合法的url列表
成功返回示例:
{
"remain":4999998,
"success":2,
"not_same_site":[],
"not_valid":[]
}
2,状态码为4XX或500,表示推送失败,返回字段有:
字段
是否必选
类型
说明
error
是
int
错误码,与状态码相同
message
是
string
错误描述
常见的推送失败返回示例说明:
error | message | 含义 |
400 | site error | 站点未在站长平台验证 |
empty content | post内容为空 | |
only 2000 urls are allowed once | 每次最多只能提交2000条链接 | |
over quota | 超过每日配额了,超配额后再提交都是无效的 | |
401 | token is not valid | token错误 |
404 | not found | 接口地址填写错误 |
500 | internal error, please try later | 服务器偶然异常,通常重试就会成功 |
1, 和原来的sitemap提交接口有什么区别?
答:状态反馈更及时了,原来提交后需要登录到搜索资源平台查看提交是否成功。目前只要根据提交后返回的数据就可以判断了。
2, 已经存在的提交sitemap数据的程序代码需要做什么修改?
答:主要修改两点。第一点,提交的接口需要修改;第二点,需要处理下接口返回的信息,失败后需要根据错误进行相应处理,报错的链接是无法提交成功的
3,为什么提交成功后看不到数据变化?
答:我们反馈的是新提交链接的数量,如果您提交的链接在之前提交过(即重复提交)是不会被统计到的
4,在什么时机使用API推送提交功能效果最明显?
答:页面链接产生或发布时立即提交,这样效果是最好的
5,每次提交一条数据和多条数据有什么区别?
答:没有区别
6,重复提交已经发布的链接会有什么问题?
答:会有两个影响。第一,将浪费您提交的配额,每个站点每天可提交的数量是有限制的,如果您都提交了旧链接,当有新链接时可能因为配额耗尽无法提交。第二,如果您经常重复提交旧链接,我们会下调您的配额,您可能会失去API推送功能的权限
7,API推送可以推多少条链接?
答:API推送可提交的链接数量上限是根据您提交的新产生有价值链接数量而决定的,百度会根据您提交数量的情况不定期对上限额进行调整,提交的新产生有价值链接数量越多,可提交链接的上限越高。
什么是Sitemap
Sitemap(即站点地图)就是您网站上各网页的列表。创建并提交Sitemap有助于百度发现并了解您网站上的所有网页。您还可以使用Sitemap提供有关您网站的其他信息,如上次更新日期、Sitemap文件的更新频率等,供百度Spider参考。
百度对已提交的数据,不保证一定会抓取及索引所有网址。但是,我们会使用Sitemap中的数据来了解网站的结构等信息,这样可以帮助我们改进抓取策略,并在日后能更好地对网站进行抓取。
此外,Sitemap 与搜索排名没有关系。
百度Sitemap协议支持文本格式和xml格式,可以根据自己情况来选择任意一种格式组织sitemap。具体格式说明及示例如下:
在一个txt文本列明需要向百度提交的链接地址,将txt文本文件通过搜索资源平台进行提交
http://www.example.com/repaste/101562698_5230191316.html
http://www.example.com/repaste/101586283_5230215075.html
http://www.example.com/repaste/101639435_5230310576.html
此文本文件需要遵循以下指南:
· 文本文件每行都必须有一个网址。网址中不能有换行。
· 不应包含网址列表以外的任何信息。
· 您必须书写完整的网址,包括 http。
· 每个文本文件最多可包含 50,000 个网址,并且应小于10MB(10,485,760字节)。如果网站所包含的网址超过 50,000 个,则可将列表分割成多个文本文件,然后分别添加每个文件。
· 文本文件需使用 UTF-8 编码或GBK编码。
单个xml数据格式如下:
<?xml version="1.0" encoding="utf-8"?>
<!-- XML文件需以utf-8编码-->
<urlset>
<!--必填标签-->
<url>
<!--必填标签,这是具体某一个链接的定义入口,每一条数据都要用<url>和</url>包含在里面,这是必须的 -->
<loc>http://www.yoursite.com/yoursite.html</loc>
<!--必填,URL链接地址,长度不得超过256字节-->
<lastmod>2009-12-14</lastmod>
<!--可以不提交该标签,用来指定该链接的最后更新时间-->
<changefreq>daily</changefreq>
<!--可以不提交该标签,用这个标签告诉此链接可能会出现的更新频率 -->
<priority>0.8</priority>
<!--可以不提交该标签,用来指定此链接相对于其他链接的优先权比值,此值定于0.0-1.0之间-->
</url>
<url>
<loc>http://www.yoursite.com/yoursite2.html</loc>
<lastmod>2010-05-01</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
</urlset>
上述Sitemap向百度提交了一个url:http://www.yoursite.com/yoursite.html
若有多条url,按照上述格式重复<url></url>之间的片断,列明所有url地址,打包到一个xml文件,向搜索资源平台进行提交。
第一,一个Sitemap文件包含的网址不得超过 5 万个,且文件大小不得超过 10 MB。如果您的Sitemap超过了这些限值,请将其拆分为几个小的Sitemap。这些限制条件有助于确保您的网络服务器不会因提供大文件而超载。
第二,一个站点支持提交的sitemap文件个数必须小于5万个,多于5万个后会不再处理,并显示“链接数超”的提示。
第三,如果验证了网站的主域,那么Sitemap文件中可包含该网站主域下的所有网址。
第四,搜索资源平台sitemap文件提交已不再支持索引型文件形式,历史提交的索引型文件已不再进行抓取,建议站长及时删除,重新进行资源提交。
第一步,将需提交的网页列表制作成一个Sitemap文件,文件格式请阅读百度Sitemap协议都支持哪些格式。
第二步,将Sitemap文件放置在网站目录下。比如您的网站为example.com,您已制作了一个sitemap_example.xml的Sitemap文件,将sitemap_example.xml上传至网站根目录即example.com/sitemap_example.xml
第三步,登录百度搜索资源平台,确保提交Sitemap数据的网站已验证归属。
第四步,进入Sitemap工具,点击“添加新数据”,文件类型选择“URL列表”,填写抓取周期和Sitemap文件地址
最后,提交完之后,可在Sitemap列表里看到提交的Sitemap文件,如果Sitemap文件里面有新的网站链接,可以选择文件后,点击更新所选,即对更新的网站链接进行了提交。
百度推出了移动Sitemap协议,用于将网址提交给移动搜索收录。百度移动Sitemap协议是在标准Sitemap协议基础上制定的,增加了<mobile:mobile/>标签,它有四种取值:
<mobile:mobile/> :移动网页
<mobile:mobile type="mobile"/> :移动网页
<mobile:mobile type="pc,mobile"/>:自适应网页
<mobile:mobile type="htmladapt"/>:代码适配
无该上述标签表示为PC网页
下方样例相当于向百度移动搜索提交了一个移动网页:http://m.example.com/index.html,向PC搜索提交了一个传统网页:http://www.example.com/index.html,同时向移动搜索和PC搜索提交了一个自适配网页http://www.example.com/autoadapt.html:
<?xml version="1.0" encoding="UTF-8" ?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:mobile="http://www.baidu.com/schemas/sitemap-mobile/1/">
<url>
<loc>http://m.example.com/index.html</loc>
<mobile:mobile type="mobile"/>
<lastmod>2009-12-14</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>http://www.example.com/index.html</loc>
<lastmod>2009-12-14</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>http://www.example.com/autoadapt.html</loc>
<mobile:mobile type="pc,mobile"/>
<lastmod>2009-12-14</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>http://www.example.com/htmladapt.html</loc>
<mobile:mobile type="htmladapt"/>
<lastmod>2009-12-14</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
</urlset>
按照移动Sitemap协议做好Sitemap后,在Sitemap工具点击添加新数据提交,与提交普通Sitemap方式一致。
百度Spider会参考设置周期抓取Sitemap文件,因此请根据Sitemap文件内容的更新(比如增加新url)来设置。请注意若url不变而仅是url对应的页面内容更新(比如论坛帖子页有新回复内容),不在此更新范围内。Sitemap工具不能解决页面更新问题。
Sitemap数据提交后,一般在1小时内百度会开始处理。在以后的调度抓取中,如果您的sitemap支持etag,我们会更频繁抓取sitemap文件,从而及时发现内容更新;否则抓取的周期会比较长。
百度对已提交的数据,不保证一定会抓取及收录所有网址。是否收录与页面质量相关。
不会。Sitemap 中的“priority”提示只是说明该网址相对于您自己网站上其他网址的重要性,并不会影响网页在搜索结果中的排名。
不会。网址在 Sitemap 中的位置并不会影响百度对它的识别或使用方式。
因为转码问题建议最好不要包含中文。
自动推送JS代码是百度搜索资源平台最新推出的轻量级链接提交组件,站长只需将自动推送的JS代码放置在站点每一个页面源代码中,当页面被访问时,页面链接会自动推送给百度,有利于新页面更快被百度发现。
为了更快速的发现站点每天产生的最新内容,百度搜索资源平台推出API推送工具,产品上线后,部分站长反馈使用API推送方式的技术门槛较高,于是我们顺势推出更低成本的JS自动推送工具。一步安装便可实现页面自动推送,低成本,高收益。
站长需要在每个页面的HTML代码中包含以下自动推送JS代码:
<script>
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else{
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
如果站长使用PHP语言开发的网站,可以按以下步骤操作:
1、创建名为“baidu_js_push.php”的文件,文件内容是上述自动推送JS代码;
2、在每个PHP模板页文件中的 <body> 标记后面添加一行代码:
<?php include_once("baidu_js_push.php") ?>
基于自动推送的实现原理问题,当新页面每次被浏览时,页面URL会自动推送给百度,无需站长汇总URL再进行API推送操作。
借助用户的浏览行为来触发推送动作,省去了站长人工操作的时间。
已经在使用普通收录提交里的API推送(或sitemap)的网站还需要再部署自动推送代码吗?
二者之间互不冲突,互为补充。已经使用API推送的站点,依然可以部署自动推送的JS代码,二者一起使用。
自动推送由于实现便捷和后续维护成本低的特点,适合技术能力相对薄弱,无能力支持全天候实时主动推送程序的站长。
站长仅需一次部署自动推送JS代码的操作,就可以实现新页面被浏览即推送的效果,低成本实现链接自动提交。
同时,我们也支持API推送和自动推送代码配合使用,二者互不影响。
快速收录工具可以向百度搜索主动推送资源,缩短爬虫发现网站链接的时间,对于高实效性内容推荐使用快速收录工具,实时向搜索推送资源。
开发者可通过快速收录工具,向百度搜索主动提交站点新增的高时效性资源,缩短爬虫发现网站链接的时间,一般情况下48小时内即可实现收录。
需要注意的是,快速收录仅限于提交移动端页面及移动端自适应页面。
开发者将站点与小程序相关联,提交适配规则,顺利将较多的H5资源替换为小程序资源,使小程序在百度搜索中获得较多分发与展现,就能优先获得快速收录权益。
如果开发者尚未开通小程序,且在快速收录工具界面有“一键创建并关联小程序”字样,点击即可一键创建并关联小程序,然后便可以参考《配置 URL 适配规则》提交适配规则,将H5资源替换为小程序资源。
如果开发者尚未开通小程序,且在快速收录工具界面没有“一键创建并关联小程序”字样,可在智能小程序开发者平台参考《智能小程序注册指导文档》创建发布小程序,然后参考《关联 H5 站点》关联站点,最后提交适配规则,将H5资源替换为小程序资源,可参考《配置 URL 适配规则》。
如果开发者已开通小程序,可直接在智能小程序开发者平台关联H5站点并提交适配规则,可分别参考《关联 H5 站点》《配置 URL 适配规则》。
特别提醒的是,一个小程序只能为一个站点带来权益,请开发者合理设置关联,确保小程序与H5站点的稳定关联状态,以便权益正常使用、适配正常生效。如果站点与小程序的关联关系不在了,快速收录权益也将失效。
快速收录包含手动提交和API提交两种方式,使用API提交时请使用平台提供的最新接口进行推送。
提交资源即占用配额,请谨慎选择提交方式,并尽量保证站点符合移动体验标准,提交优质资源。开发者可参考《百度搜索优质内容指南》及《百度APP移动搜索落地页体验白皮书5.0》,优化资源质量。
另外,如果网站已通过HTTPS认证工具验证为HTTPS网站,请确保所提交链接的协议头为HTTPS。
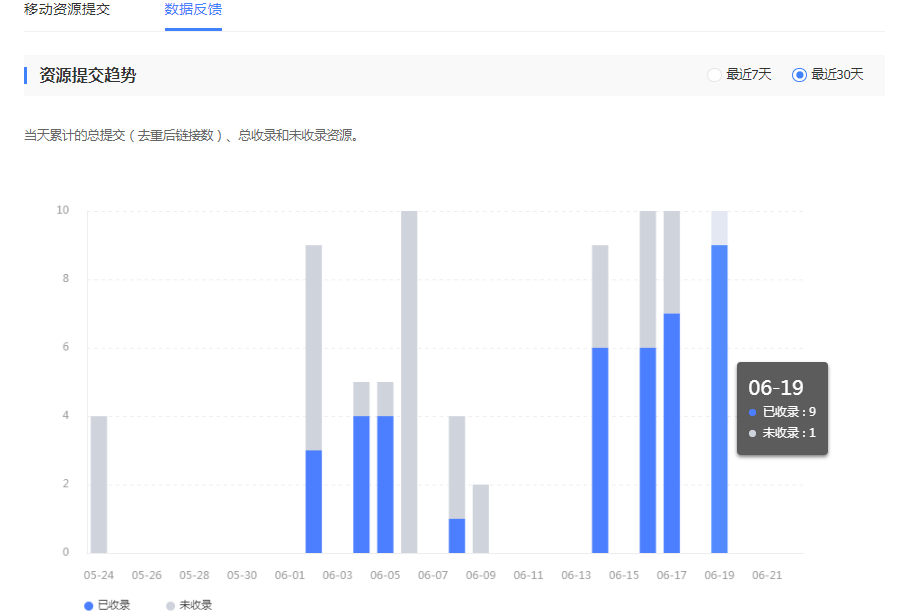
提交资源后,可通过“数据反馈”查看资源提交量及收录情况。
页面已经无效,无法对用户提供任何有价值信息的页面就是死链接,包括协议死链和内容死链两种形式:
1)协议死链:页面的TCP协议状态/HTTP协议状态明确表示的死链,常见的如404、403、503状态等。
2)内容死链:服务器返回状态是正常的,但内容已经变更为不存在、已删除或需要权限等与原内容无关的信息页面。
目前内容死链召回存在召回率的风险,所以建议各位站长尽量使用协议死链,以保证平台工具更好地发挥其作用。
当网站死链数据累积过多时,并且被展示到搜索结果页中,对网站本身的访问体验和用户转化都起到了负面影响。另一方面,百度检查死链的流程也会为网站带来额外负担,影响网站其他正常页面的抓取和索引。
第一步,处理网站已存在的死链,制作死链文件筛查网站内部存在的死链,并将这些死链页面设置成为404页面,即百度访问它们时返回404代码。将需提交的死链列表制作成一个死链文件,制作方法请参阅帮助文档(与sitemap格式及制作方法一致)
第二步,将死链文件放置在网站根目录下
比如您的网站为example.com,您已制作了一个silian_example.xml死链文件,则将silian_example.xml上传至网站根目录即example.com/silian_example.xml。特别提醒,索引型死链sitemap文件不予处理,请勿提交索引型死链sitemap文件。
第三步,登录百度搜索资源平台
第四步,提交网站并验证归属:具体验证网站归属方法可见帮助文档
第五步,提交死链数据
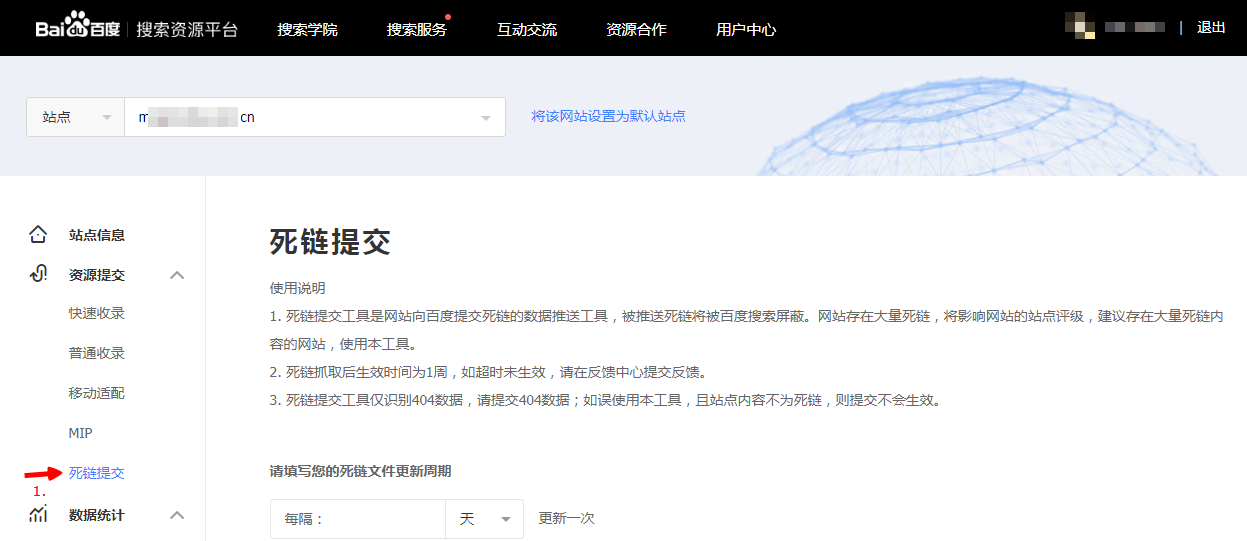
1.通过搜索资源平台-搜索服务-资源提交-死链提交,到达操作页面;
2.填写死链文件更新周期,可选“每隔xx小时/天更新一次”;
3.填写死链文件地址,请留意提交框右侧的配额提示;
4.管理已提交的死链列表,可查看死链文件状态和死链处理状态。
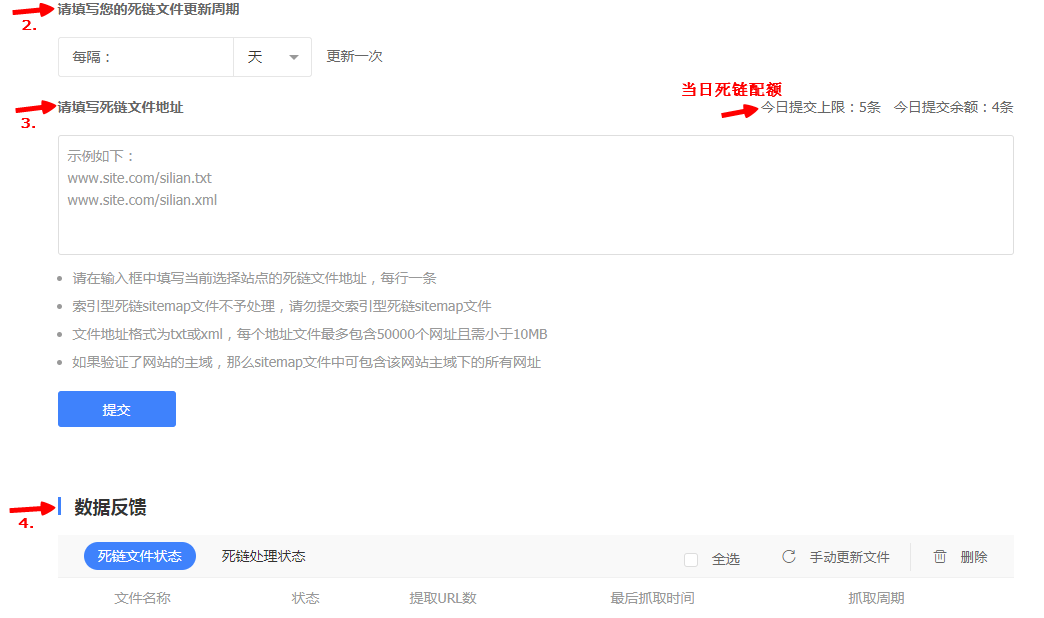
提交完之后,可在死链工具列表里看到提交的死链文件,如果死链文件里面有新的死链,可以选择文件后,点击更新所选,即对更新的死链链接进行了提交。整体流程如下图:

1)首先您要将改版前的旧链接全部通过301跳转到改版后的新链接,并且这种跳转必须是一一对应的关系,不能出现多条旧链接跳转到一条新链接,或者一条旧链接在不同时间内跳转到不同新链接的情况。
2)如果改版后产生新的站点,无论是www主站点还是二级域名,都需要将新站点在百度搜索资源平台进行验证,以保证明您拥有该站点的管理权限。
当一个站点的域名或者目录发生变化时,例如a.com变为b.com,或者a.com/b变成a.com/c,如果想让百度快速收录变化之后的新链接、用以替换之前的旧链接,那么您就需要使用百度搜索资源平台的网站改版工具来提交您的改版关系,加速百度对已收录链接的新旧替换。目前网站改工具支持以下方式的改版:
1)换域名:仅域名发生了变换,如www.a.com变为[url]www.b.com[/url],而目录结构没有任何变化。可以在网站改版工具的“添加改版规则”——“站点改版”处,添加改版前后的两个域名,提交即可。注意此处提交的前后域名必须是不同的。
2)目录结构改版:不管域名是否改变,目录结构发生了变化,如www.a.com/a变为www.a.com/b,或又如www.a.com/c变为c.a.com。可以在网站改版工具的“添加改版规则”——“规则改版”处,提交新旧目录正则式,正则式的书写方式详见“正则格式说明”。
3)部分URL改版:当您的网站点仅有部分URL发生了改版,正则式不能满足改版形式的表达,或前两种方式提交的规则校验失败,您还可以通过提交url对文件,将已经改版的旧链接和对应的新链接提交给百度:文件格式为每行前后两个url,分别是改版前旧链接和跳转后新链接,中间用空格分隔,一个文件最多可以提交5万对url,您可以提交多个文件。另外您还可以在输入框中直接输入url对,格式与文件相同,但这处一次性仅限提交2000对url。
在您提交改版规则后, 网站改版工具会提供状态说明:
1)规则校验中:百度搜索资源平台会对管理员提交的改版规则进行校验,当认为实际情况与您提交的规则相符时,才会对规则进行生效处理,这个校验时间最长为2小时。
2)校验失败:当百度搜索资源平台发现站点存在如下问题时,会判为校验失败,不会进行后续的生效处理:
a、提交重复规则:如果您当前提交的规则包含了正在生效的规则(状态为改版中或改版完成),则认定新提交的规则无效,您需要删除旧规则后再提交新规则,或者直接修改新规则。
b、未设置301跳转:对于存在改版关系的url对,我们要求通过301进行跳转。
c、旧链抓取失败:改版规则中旧链接无法正常访问。
d、新链抓取失败:改版规则中新链接、即跳转过去的链接无法正常访问。
e、跳转关系与规则不符:您提交的三种规则必须是真实的url对跳转关系,否则不予通过。
f、url与所提交站点不匹配:三种规则都会要求您填写新旧链接对应的站点信息,如果提交的url对与站点信息不匹配会报此错误信息。
g、正则格式不正确:请按照规定的格式进行填写,详见:“正则格式说明”。
h、url对文件格式不正确:要求的url对文件格式为:每行有两个url,用空格分隔,最多5万行。
i、多跳一:链接跳转关系中出现了多条链接跳转到一条链接的情况。
这些错误信息会抽样展示在错误详情页面中。
3)无需改版:网站改版工具只适用于改版前的旧链接已被百度收录,对于未收录的旧链接,我们无法进行处理。
4)改版进行中:您提交的改版规则通过校验后,百度搜索资源平台会进行生效处理,这个过程最长为48小时。
5)改版完成:百度已经根据您提交的改版规则对新旧链接进行了替换。
请注意,改版完成后,百度会持续一段时间例行检查改版规则在您网站的生效状态,一旦连续发现改版规则出现校验失败原因中的问题,该规则的状态会由“改版完成”调整为“校验失败”状态,此时需要您修正站内异常并重新提交改版规则。所以请尽可能长时间(至少三个月)保持新旧链接的跳转关系。
以站点news.a.com改版到站点a.com/news为例:
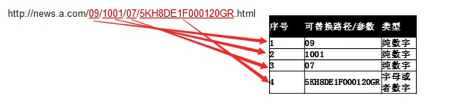
改版前url地址为http://news.a.com/09/1001/07/5KH8DE1F000120GR.html,
其对应的改版后url地址为http://a.com/news/09/1001/07/5KH8DE1F000120GR.html
步骤一:确定改版前链接中的可替换参数或者路径,得到其位置序号和类型。
改版前页url:
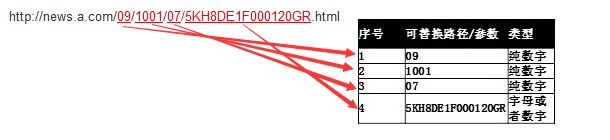
根据网站自身url的层次结构,其中09,1001,07和5KH8DE1F000120GR为动态可替换的路径。除5KH8DE1F000120GR为字母和数字混合外,其余均为纯数字。
步骤二:根据可替换参数或路径的类型,得到改版后链接的表达形式。
使用正则匹配符号(\d+)或者(\w+)表示该路径或参数。(\d+)表示纯数字字符串,(\w+)表示字母数字下划线组成的字符串。

步骤三:根据改版后url,以及可替换参数在步骤一中的位置序号,依次用${1},${2},……表示替换掉改版前url中的可替换参数或路径,得到改版后链接pattern形式。

至此,便得到了改版前后的规则:
http://news.a.com /(\d+)/(\d+)/(\d+)/(\w+).html
http://a.com/news/${1}/${2}/${3}/${4}.html
一、网站异常
1、dns异常
当Baiduspider无法解析您网站的IP时,会出现DNS异常。可能是您的网站IP地址错误,或者域名服务商把Baiduspider封禁。请使用WHOIS或者host查询自己网站IP地址是否正确且可解析,如果不正确或无法解析,请与域名注册商联系,更新您的IP地址。
2、连接超时
抓取请求连接超时,可能原因服务器过载,网络不稳定
3、抓取超时
抓取请求连接建立后,下载页面速度过慢,导致超时,可能原因服务器过载,带宽不足
4、连接错误
无法连接或者连接建立后对方服务器拒绝
二、链接异常
1、访问被拒绝
爬虫发起抓取,httpcode返回码是403
2、找不到页面
爬虫发起抓取,httpcode返回码是404
3、服务器错误
爬虫发起抓取,httpcode返回码是5XX
4、其他错误
爬虫发起抓取,httpcode返回码是4XX,不包括403和404


1、结合谈外链判断对站点的问题外链进行处理,并对以后的链接建设起到积极的作用;
2、基于我们提供的外链数据,您可以进行多种维度的重组聚合,进而了解自身在外链建设上的情况以及与竞争对手的对比情况。
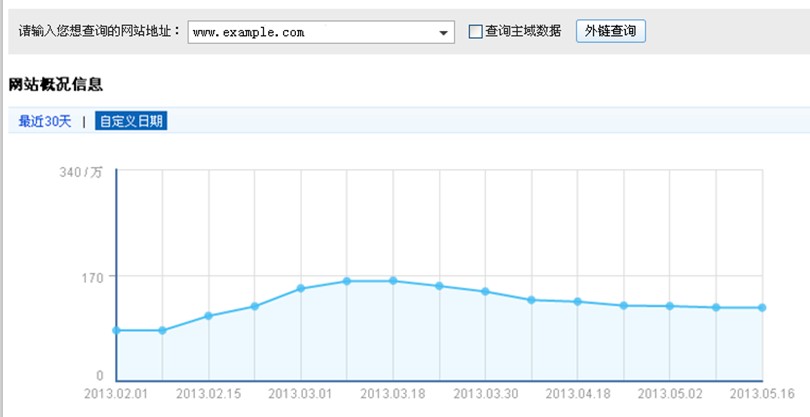
此数据是未经百度搜索计算过滤的原始数据,仅供参考。登录您在百度站长平台注册的账号,进入站长工具à网站分析à外链分析,此时您可以:
第一、查看一段时间内您网站自身或某其他网站的外链趋势走向;
第二、进一步可查看您网站自身的具体外链数据。当您苦恼于曾经在外链建设过程中某些外链影响到您网站在百度系统中的评价时,那么拒绝外链功能可以使您不再苦恼,同时支持单条拒绝和批量拒绝。其中,批量拒绝可分为四个级别进行批量操作:主域、站点、目录、页面,您可以按照需要进行操作,每次最高1000条。结合谈外链判断,对指向您网站的问题外链进行拒绝操作,当问题外链提交至百度系统中并在一段时间的更新后,系统将根据情况自动调整对您网站的评价;
第三、如果您因疏忽而误将重要外链提交拒绝,那么也不要过于担心,可以通过撤销拒绝来恢复。当然,我们希望您不要过于粗心,系统难免出现问题将造成不必要的损失;
第四、您可以查看并下载任一网站的外链数据,以便于您进行自身网站外链分析以及竞争对手对比分析。不同的聚合重组,将使您得到多种重要的结论。举两个例子:
(1)自身某专题页排名不如竞争对手,当其他方面相差不大的情况下怀疑是外链因素造成。此时就可以将两个专题页的外链进行聚合对比分析,找出差距,兼顾质量和数量,着重分析外链产生的原因及过程。当然,分析的数据前提是根据谈外链判断将问题外链排除之后的数据,同时欢迎举报。
(2)按anchor进行聚类,可分析某页面传播过程中用户以及其他网站对该内容的定位,您在之后的外链建设传播过程进行适度调整。
总之,详细外链数据下载后根据自身需求可进行多方面的聚合分析,各位站长也可以在站长社区show出你的分析案例。
第一,什么是拒绝外链?
外链是百度判断网页重要性数百个因素中很重要的一个方面。百度尽可能避免第三方网站上的行为对您网站产生负面影响。但某些情况下,一些垃圾、低质量导入链接可能会影响百度对您网站的评价。例如,网络上大量的垃圾内容或质量很差的链接或者您购买了付费链接、采用了违反百度站长指南的链接手段。
首先,我们建议您从链接来源页面尽可能多的删除垃圾内容和链接。
其次,再没有任何其他措施可以删除剩余垃圾链接的情况下,就可以利用拒绝外链工具来通知百度在评价您网页之时忽略掉该链接。
第二,拒绝外链应该注意什么?
当您发现指向您网站的垃圾链接、虚假或低质量链接数量可观,同时确定这些链接会给您的网站造成负面影响,再使用该工具,否则请勿使用。当您确认拒绝后将无法撤销或删除,请谨慎使用。
如果您存在购买链接、群发外链、挂黑链等试图操作搜索引擎排序的作弊行为,我们不能保证短时间内去除掉该垃圾外链对您网站的负面影响,这需要数周乃至更长的时间来验证,请您耐心等待。
第三,如何使用拒绝外链工具?
请先选择您希望拒绝的外链类别,类别主要分为主域、站点、目录和页面。主域是指在域名服务商注册的域名,如:example.com;站点是指网站的根目录之前的url,网站地址,如:www.example.com/;目录是指站点后以“/”结尾的,如:www.example.com/a/;页面是指一个具体页面的url,如:www.example.com/a/978.html。
以url:www.iqiyi.com/fun/20130308/4319a1351bb0167d.html为例,该url即为一个页面;主域为iqiyi.com;站点为www.iqiyi.com;www.iqiyi.com/fun/为一个目录。
根据您选择的类别填写相对应的url提交拒绝信息即可。我们需要一定的时间来处理您提交的信息,拒绝外链生效的周期为数周,请您耐心等待。
首先,Baiduspider会根据网站服务器压力自动进行抓取频次调整。其次,如果Baiduspider的抓取影响了网站稳定性,站长可以通过此工具调节Baiduspider每天抓取您网站的频次上限。
强调1:调整抓取频次上限不等于调高抓取频次。强调2:建议您慎重调节抓取频次上限值,如果抓取频次过小则会影响Baiduspider对网站的收录。
Robots是站点与spider沟通的重要渠道,站点通过robots文件声明本网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中声明 该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
robots.txt文件应该放置在网站根目录下。举例来说,当spider访问一个网站(比如 http://www.abc.com)时,首先会检查该网站中是否存在http://www.abc.com/robots.txt这个文件,如果 Spider找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。
网站 URL | 相应的 robots.txt的 URL |
http://www.w3.org/ | http://www.w3.org/robots.txt |
http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
http://w3.org/ | http://w3.org/robots.txt |
robots文件往往放置于根目录下,包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
"<field>:<optional space><value><optionalspace>"
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:该项的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只受到"User-agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。"Disallow:"说明允许robot访问该网站的所有url,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
使用"*"and"$":Baiduspider支持使用通配符"*"和"$"来模糊匹配url。
"*" 匹配0或多个任意字符
"$" 匹配行结束符。
最后需要说明的是:百度会严格遵守robots的相关协议,请注意区分您不想被抓取或收录的目录的大小写,百度会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议无法生效。
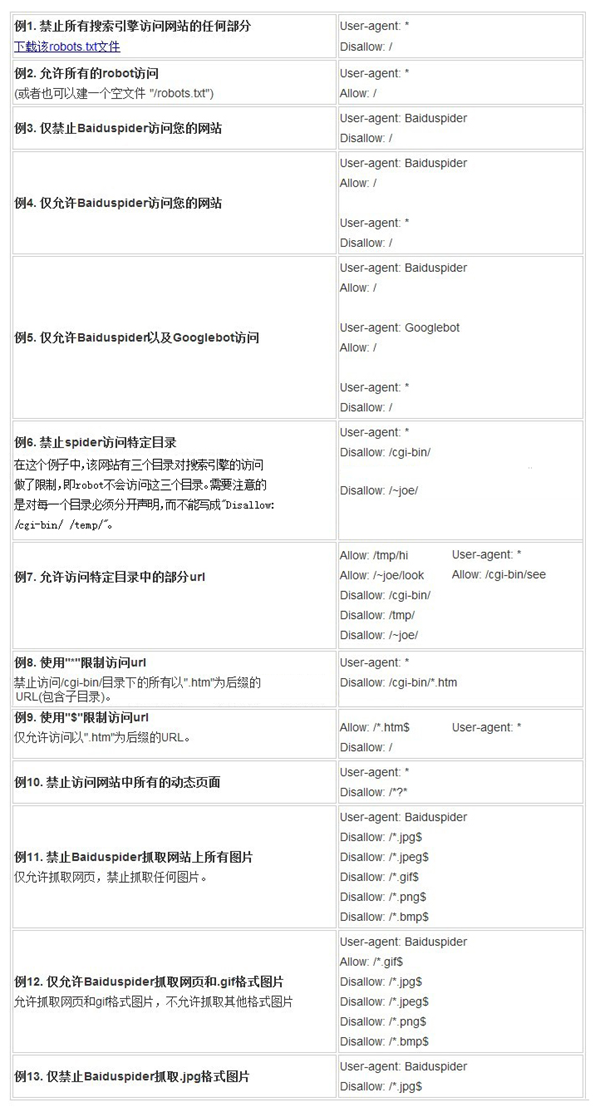
robots文件是搜索生态中很重要的一个环节,同时也是一个很细节的环节。很多站长同学在网站运营过程中,很容易忽视robots文件的存在,进行错误覆盖或者全部封禁robots,造成不必要损失!
那么如果误操作封禁了robots怎么办?今天我们请到了厦门258网站运营负责人——郑军伟,为我们分享网站robots误封禁后该如何操作?
【案例背景】
网站开发2.0版本,技术选择了在线开发,为了避免搜索引擎抓取开发版本,要求技术人员设置了Robots封禁处理。2.0版本开发周期1个月,1个月后网站版本迭代,直接覆盖了1.0版本,包括Robots封禁文件,2天后发现流量大幅下降,检查收录发现800万收录降至0条,关键词大量掉线。

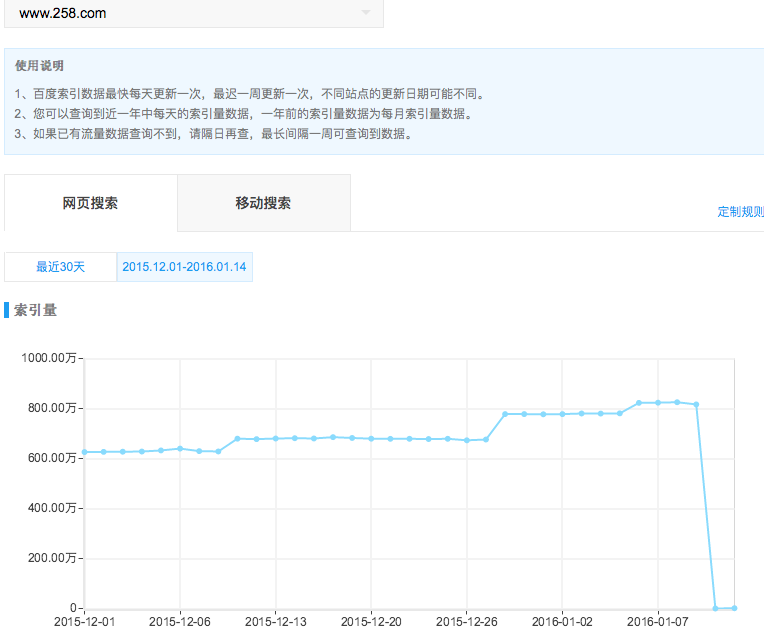
【处理方式】
1.修改Robots封禁为允许,然后到百度搜索资源后台检测并更新Robots。
2.在百度搜索资源后台抓取检测,此时显示抓取失败,没关系,多点击抓取几次,触发蜘蛛抓取站点。
3.在百度搜索资源后台抓取频次,申请抓取频次上调。
4.百度反馈中心,反馈是因为误操作导致了这种情况的发生。
5.百度搜索资源后台链接提交处,设置数据API推送(实时)。
6.更新sitemap网站地图,重新提交百度,每天手动提交一次。
以上处理完,接下来就是等待了,万幸,2天的时间数据开始慢慢回升,到第3天基本回升到正常状态!
【案例总结】
本次事故绝对是运营生涯的一次败笔,总结反思一下,希望大家避免类似问题。
1.产品开发一定要避免在线开发,不能为了省事不搭建开发环境。
2.产品迭代要有流程记录,开发时做了那些设置处理,那些是不需要放出来的,那些是必须放出来的,要非常清楚。
3.要经常关注百度搜索资源后台,关注相关数据变化,从数据变化中及时发现问题
9月11日,百度搜索robots全新升级。升级后robots将优化对网站视频URL收录抓取情况。仅当您的网站包含不希望被视频搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
如您的网站未设置robots协议,百度搜索对网站视频URL的收录将包含视频播放页URL,及页面中的视频文件、视频周边文本等信息,搜索对已收录的短视频资源将对用户呈现为视频极速体验页。此外,综艺影视类长视频,搜索引擎仅收录页面URL。
详情见:视频极速体验解决方案
logo提交后为何没有展现?
答:您好,logo展现目前只针对优质站点进行审核和展现,如果您站为优质站点,logo提交后通常会在1到2周内进行审核和展现,具体情况请参考百度站长社区的详情帖。
新建的网站未收录怎么办?
答:页面是否被收录,与页面是否具有价值有关,原则上内容越贴近用户的搜索需要,网页就会越快地被搜索引擎收录。但通常情况下页面从产生到收录需要一定周期,时间从几分钟到几天不等,这取决于网页的搜索价值和重要性的高低。长时间不收录的原因可能包括:
1) 页面被惩罚整站或目录没有进行收录,
2) 网页没有被搜索引擎发现,因为网页没有放置外部链接,本身是个孤岛页面。
针对第一种情况,首先请查看网站是否出现过无法打开或连通异常的状况,可以接助站长平台抓取诊断工具来进行判断。同时查看网站是否有过不良信息的收录,如果网站已经恢复正常并可以正常连通和抓取,可以提交到反馈中心进行反馈。针对网站始终没有被百度抓取的情况,建议您使用搜索资源平台的普通收录工具进行提交。
网站在搜索url或使用domain语法搜索时,出现了不相关的结果的问题?
答:通常情况下,搜索url是为了确定该页面是否已被搜索引擎收录,除此以外的其他自然结果,均为以该url作为关键词,在网页库中进行搜索而得出的自然结果。这些自然结果的内容如何,与网页所处的网站是否存在问题并无关联。
由网站自身原因(改版、暂停服务等)、客观原因(服务器故障、政策影响等)造成的网站较长一段时间都无法正常访问,百度搜索引擎会认为该站属于关闭状态。站长可以通过闭站保护工具进行提交申请,申请通过后,百度搜索引擎会暂时保留索引、暂停抓取站点、暂停其在搜索结果中的展现。待网站恢复正常后,站长可通过闭站保护工具申请恢复,申请审核通过后,百度搜索引擎会恢复对站点的抓取和展现,站点的评价得分不会受到影响。
闭站保护注意事项1)站长关闭站点后应立即申请闭站保护,若申请不及时,站点很可能被判为死链,影响后续的收录和展现。
2)支持两种闭站方法,全站HTTP状态码设置为404或者切断电源关闭服务器,不支持使用DNS方法闭站,noip不会通过闭站申请校验。
3)申请闭站保护,若通过审核将在一天内生效;申请取消闭站保护,若通过审核将在2天以内生效。
4)闭站保护期最长为180天,超过180天将自动取消闭站保护。
5)使用闭站工具只能保留您网站的索引量,但不保证网站的排名不变
6) 闭站保护期间,为了满足用户的寻址需求,首页会被豁免,不予屏蔽
假设您的网站是www.abc.com,第三方网站是www.example.com。
内链死链:在您网站上发现同一个域名内的死链,即:如果在http://www.abc.com/1.html上发现了一条死链http://www.abc.com/2.html,那么我们称http://www.abc.com/2.html为内链死链;
链出死链:在您网站上发现的链接到其他网站的死链,即:如果在http://www.abc.com/1.html上发现了一条死链http://www.example.com/1.html,那么我们称http://www.example.com/1.html为外链死链;
链入死链:在其他网站上发现的链接到您网站的死链,即:如果在http://www.example.com/2.html上发现了死链http://www.abc.com/2.html,那么我们称http://www.abc.com/2.html为链入死链。
死链链接:Baiduspider在尝试抓取该网页时,该网页返回了404代码; 目前死链链接只针对协议死链,后续会陆续增加跳转死链和内容死链。
死链前链:从该网页经过一次点击即可到达当前死链链接,称该网页为当前死链链接的前链,即死链前链。
锚文本:在死链前链这个网页上发现的对应该死链链接的文本信息。
发现时间:Baiduspider最近一次抓取该死链链接的时间。
1、结合《谈外链判断》对站点的问题外链进行处理,并对以后的链接建设起到积极的作用;
2、基于我们提供的外链数据,您可以进行多种维度的重组聚合,进而了解自身在外链建设上的情况。
此数据是未经百度搜索计算过滤的原始数据,仅供参考。登录您在百度站长平台注册的账号,进入站长工具->优化与维护->链接分析,此时您可以:
第一、查看一段时间内您网站自身的外链趋势走向;
第二、进一步可查看链接到您网站的外链所在的主域以及外链数量。
第三、您可以查看并下载您网站的具体外链数据,以便于您进行自身网站外链分析。不同的聚合重组,将使您得到多种重要的结论。举两个例子:
(1)自身某专题页排名不高,当其他方面找不到原因的时候怀疑是外链因素造成。此时就可以将专题页的外链进行聚合分析,兼顾质量和数量,着重分析外链产生的原因及过程。当然,分析的数据前提是根据谈外链判断将问题外链排除之后的数据,同时欢迎举报。
(2)按anchor进行聚类,可分析某页面传播过程中用户以及其他网站对该内容的定位,您在之后的外链建设传播过程进行适度调整。
总之,详细外链数据下载后根据自身需求可进行多方面的聚合分析。
问:外链多长时间更新?
答:目前预计一周更新一次,请您耐心等待。
提升搜索用户在百度移动搜索的检索体验,会给对应PC页面的手机页面在搜索结果处有更多的展现机会,需要站点向百度提交主体内容相同的PC页面与移动页面的对应关系,即为移动适配。为此,百度移动搜索提供“移动适配”服务,如果您同时拥有PC站和手机站,且二者能够在内容上对应,即主体内容完全相同,您可以通过移动适配工具进行对应关系提交。
站长通过移动适配工具提交pattern级别或者url级别的PC页与手机页对应关系,若可以成功通过校验,将有助于百度移动搜索将移动用户直接送入对应的手机页结果。积极参与“移动适配”,将有助于您的手机站在百度移动搜索获得更多流量,同时以更佳的浏览效果赢取用户口碑。
当您同时拥有移动站点和PC站点、且移动页面和PC页面的主体内容完全相同,就可以在通过百度搜索资源平台提交正确的适配关系,获取更多移动流量。
第一步,注册并登录百度搜索资源平台
第二步,提交PC网站并验证站点与ID的归属关系,具体验证网站归属方法可见帮助文档
第三步,站点验证后,进入“搜索服务”——“资源提交”——“移动适配”,选择具体需要进行移动适配的PC站,然后“添加适配关系”
第四步,根据自己提交的适配数据特点,选择适合您的提交方式:
目前移动适配工具支持规则适配提交URL适配提交,无论您使用哪种方式都需要先指定PC与移动站点,此举可以令平台更加快速地检验您提交的数据、给出反馈,顺利生效。同时您在之后步骤中提交的适配数据中必须包含指定的站点,否则会导致校验失败。
1)规则适配:当pc地址和移动地址存在规则(pattern)的匹配关系时(如PC页面www.xxx.com/picture/12345.html,移动页面m.xxx.com/picture/12345.html),可以使用规则适配,添加pc和移动的正则表达式,正则的书写方式详见《正则格式说明》。我们强烈建议您使用规则适配,一次提交成功生效后,对于新增同规则的URL可持续生效,不必再进行多次提交。同时该方式处理周期相对URL适配更短,且易于维护和问题排查,是百度推荐使用的提交方式。
2)URL适配:当规则适配不能满足适配关系的表达时,您可以通过“URL对文件上传”功能,将主体内容相同的pc链接和移动链接提交给百度:文件格式为每行前后两个url,分别是pc链接和移动链接,中间用空格分隔,一个文件最多可以提交5万对url,您可以提交多个文件。另外您还可以选择“URL对批量提交”,在输入框中直接输入url对,格式与文件相同,但此处一次性仅限提交2000对url。
第五步,提交适配数据后,关注移动适配工具会提供状态说明,若未适配成功,可根据说明文字和示例进行相应的调整后更新提交适配数据。
PC站点下开辟某个目录存放移动适配页面、作为移动适配“站”时,依然会有提交移动适配数据的需求,如:http://www.a.com/a.html 适配到http://www.a.com/m/a.html。虽然从长远角度看,这种行为对搜索引擎极不友好,百度(包括GOOGLE)一直不赞成不鼓励这种建方式。但为了满足该需求,百度搜索资源平台移动适配工具依然提供满足此需求的功能。
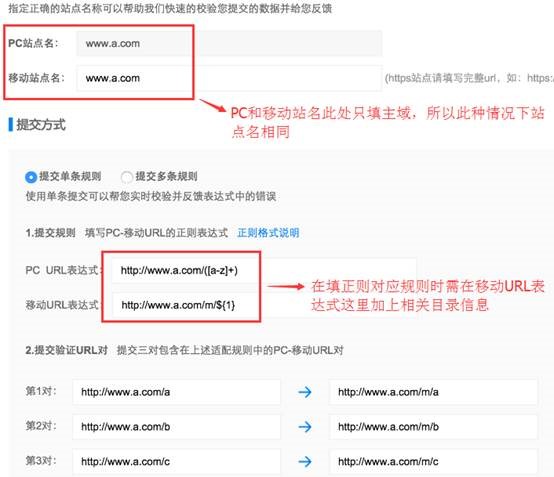
您可以先在下拉菜单中选择准确的站点域名,再点击“+添加适配关系”。也可以在默认的www主域下“+添加适配关系”。
进入“添加新数据”界面后,“指定PC-移动站点”处填写的移动站点名,要与PC站点名一致,然后在提交规则处填写相应的正则信息,然后增加校验用url对即可。提交数据时示例图如下:
校验中:百度搜索资源平台会对管理员提交的移动适配数据进行校验,当认为实际情况与您提交的情况相符时,才会对适配数据进行生效处理,这个校验时间大约为10天。目前“校验中”的适配数据不能删除。
校验失败:当百度搜索资源平台发现站点存在如下问题时,会判为校验失败,不会进行后续的生效处理:
a、页面不相似:PC链接和移动链接的主体内容相似度低,达不到对应关系。请检查网站页面,确认主体内容一致后再次提交
b、移动页不友好: 您提交的适配数据中移动链接为pc页或移动页面不符合广告白皮书规范,请自查确保数据无问题后再次提交
c、含有死链链接:您提交的适配数据中含有死链内容,请自查适配数据,保证无死链情况后再提交
d、未达到校验标准:提交面的“?”号获取的适配数据中,PC页面或移动页面没有收录。移动适配工具对适配数据进行正确性校验时依赖PC网页库和移动网页库中已收录的页面,如果校验时取到的PC页或移动页百度还未收录,将无法对适配数据进行检验。对于未收录的页面将推送给spider进行抓取,若收录后可进行下一次正确性检验,管理员不必再另行提交。
e、未达到校验标准:PC页面或移动页面没有收录。移动适配工具对适配数据进行正确性校验时依赖PC网页库和移动网页库中已收录的页面,如果校验时取到的PC页或移动页百度还未收录,将无法对适配数据进行检验。对于未收录的页面将推送给spider进行抓取,若收录后可进行下一次正确性检验,管理员不必再另行提交。*页面被收录不等于被建索引,收录了的页面有可能在索引量工具里查不到。
f、数据校验失败:数据流校验异常,请站点再次提交数据,进行二次校验、
g、其他原因:可能由于以下原因导致适配数据校验失败:1、pc移动页面不对应;2、pc页面展示量太低;3、正则规则错误;请网站自查是否有以上情况,如有以上情况请自查并整改,然后再次提交数据
以上错误信息会抽样展示在错误详情页面中,您可以通过点击状态说明获取

校验成功:您提交的适配数据通过校验后,百度搜索资源平台会进行生效处理,这个过程最长为10天。
校验部分成功: 您提交的适配数据中包含部分校验失败内容,失败部分可以参考校验失败的说明,其他成功部分会上线生效。
未达到校验标准:您提交的规则所涉及的页面,绝大多数未收录(区别于索引)或展现过少,平台工具为了高效处理海量规则,会将未达到校验标准的规则做延后处理,站点方面不必再做额外工作。
适配成功:百度已经根据您提交的适配数据对移动链接进行了替换。
适配部分成功:对应校验部分成功而言,那部分通过校验的数据已完成移动适配。
内容重复:此文件提交的数据被后提交的文件包含覆盖,工具后续不会再对该文件进行处理,也不会反馈处理状态
站长通过移动适配工具提供适配数据中若发现数据有误,或想更新旧的、已生效的适配关系,可以重新提交新的适配数据予以覆盖。具体如下:
1、目前“校验中”的数据不支持直接删除,若此时需要修改适配关系数据,不需要等等该数据更新状态,可以直接提交新的适配关系予以覆盖。
2、如适配数据发生校验失败,无需将其删除,直接提交新的适配关系覆盖即可。
3、若需要修改已适配成功的关系数据,无需将原适配数据删除,直接提交新的适配关系覆盖即可,待新数据适配成功后线上可生效。
1、只要PC站点与移动站点的主干一致,即可参与移动适配。举例说明:PC站点ww.abc.com.cn 移动站点m.abc.net 属于主干一致。当然我们更建议您使用主域相同的PC站点和移动站点
2、建议您尽量使用规则适配进行对应关系提交,一次提交可对于新增同规则的URL持续生效,无需多次反复提交,且处理周期相对URL提交更短,更易于维护和问题排查,是百度推荐使用的提交方式
3、使用正则格式进行规则适配,尽量使用最小的粒度来表示,这样更容易校验通过,比如:
a).确定是纯数字:([0-9]+) 或(\d+)
b).确定是纯字母:([a-zA-Z]+), 包括字母大小写的情况
c).确定是数字和字母混合串:
方法一、((?:[a-zA-Z]+[0-9]+|[0-9]+[a-zA-Z]+)[a-zA-Z0-9]+)
方法二、([a-zA-Z0-9]+)
说明:两种混合串的区别:较长的一种为严格的数字和字母混排形式,且数字 和字母交替至少出现1次;
较短的一种可支持纯数字,纯字母和数字字母混排
d).确定有中文字符:((?:%[a-zA-Z-0-9]{2,})+)
e).确定有参数值:([^&]+)
f).确定有'-'和'_'连接字符串的替换规则:将连接的各个部分分别用对应的规则替换
4、 百度搜索资源平台对适配数据的校验时间大约为10天,生效时间大约为1-2天。
5、适配成功后要继续保持正确的适配关系,我们会重复验证适配关系的有效性。
首先,对已有的对应关系持续进行适配,同时不断建设新的对应关系,增加适配覆盖的范围。其次,要确保已经提交的对应关系准确。以下是常见的对应不准确错误,请网站进行自查,并及时修改。
1、手机页不可用,比如死链。
2、robots封禁。放开对Baiduspider的robots封禁,以便Baiduspider获取您PC站与手机站之间的对应关系。
3、手机页使用了ajax等异步加载的方法加载内容主体。
4、格式错误。正则格式错误,文件格式错误等。
5、对应关系错误
1)当PC页为内容页时,应该适配到对应的手机页内容页,而实际却适配到手机页的首页/列表页
例如PC页为http://www.aaa.com/Book/2083259.aspx,适配后的手机页为http://m.aaa.con/?from=web
2)手机页本身无主体内容或主体内容过少。
3)手机页需登录才能浏览主体内容。
4)PC页内容与手机页内容不存在一一对应关系。
正确的对应关系示例:
PC页http://www.58.com/mmmshandongrencai/
手机页http://m.58.com/w/mmmshandongrencai/
以站点news.a.com适配到站点m.a.com为例:
适配PC链接地址为:http://news.a.com/09/1001/07/5KH8DE1F000120GR.html,
适配移动链接地址为:http://m.a.com/news/09/1001/07/5KH8DE1F000120GR.html
步骤一:确定适配链接中的可替换参数或者路径,得到其位置序号和类型。
适配PC链接:
根据网站自身url的层次结构,其中09,1001,07和5KH8DE1F000120GR为动态可替换的路径。除5KH8DE1F000120GR为字母和数字混合外,其余均为纯数字。
步骤二:根据可替换参数或路径的类型,得到链接的表达形式。
使用正则匹配符号(\d+)或者(\w+)表示该路径或参数。(\d+)表示纯数字字符串,(\w+)表示字母数字下划线组成的字符串。

步骤三:根据移动链接,以及可替换参数在步骤一中的位置序号,依次用${1},${2},……表示替换掉适配PC链接中的可替换参数或路径,得到适配后的移动链接的pattern形式。

至此,便得到了适配的规则:
http://news.a.com/(\d+)/(\d+)/(\d+)/(\w+).html
http://m.a.com/news/${1}/${2}/${3}/${4}.html
1、纯数字替换生成pattern例子:
eg1:url对应关系:
http://www.abc.com/26299483.html-> http://m.abc.com/26299483.html
pattern:
http://www.abc.com/([0-9]+).html-> http://m.abc.com/${1}.html
eg2:url对应关系:
http://www.abc.com/t26299483.html-> http://m.abc.com/26299483.html
pattern:
http://www.abc.com/t([0-9]+).html-> http://m.abc.com/${1}.html
2、纯字母替换生成pattern例子:
eg:url对应关系:
http://www.abc.com/fawliute/ -> http://m.abc.com/fawliute/
pattern:
http://www.abc.com/([a-zA-Z]+)/ -> http://m.abc.com/${1}/
3、字母和数字混合的字符串替换生成pattern的例子:
eg1:url对应关系:
http://www.abc.com/a1cc1n2q5y3/ -> http://m.abc.com/a1cc1n2q5y3/
pattern:
http://www.abc.com/((?:[a-zA-Z]+[0-9]+|[0-9]+[a-zA-Z]+)[a-zA-Z0-9]+)/ -> http://m.abc.com/${1}/
注意:字母和数字混合字符串,字母和数字必须交替出现至少1次
有效例子:a13b,23a9,da3bc99,42a1c
eg2:url对应关系:
http://news.abc.com/09/1001/07/5KH8DE1F000120GR.html
-> http://m.abc.com/news/09/1001/07/5KH8DE1F000120GR.html
pattern:
http://news.abc.com/([0-9]+)/([0-9]+)/([0-9]+)/([ a-zA-Z0-9]+).html
-> http://m.abc.com/news/${1}/${2}/${3}/${4}.html
4、对于字母和数字只交替出现一次的,可以分别用数字和字母进行正则替换:
eg:url对应关系:
http://www.abc.com/az123/ -> http://m.abc.com/az123/
pattern:
http://www.abc.com/([a-zA-Z]+)([0-9]+)/-> http://m.abc.com/${1}${2}/
5、中文字符串正则替换生成pattern例子:
eg:url对应关系:
http://www.abc.com/长城花园/ -> http://m.abc.com/长城花园/
pattern:
http://www.abc.com/((?:%[a-zA-Z0-9]{2,})+)/-> http://m.abc.com/${1}/
6、由'-'或者'_'连接的数字或者字母替换生成pattern的例子:
eg:url对应关系:
http://www.abc.com/byd-c3/-> http://m.abc.com/byd-c3/
pattern:
http://www.abc.com/([a-zA-Z]+)-([a-zA-Z]+)([0-9]+)/->http://m.abc.com/${1}-${2}${3}/
注意:'-'和'_'出现多次可以使用同样的方式处理
如:abc-134_x-1
7、对参数部分进行正则替换生成pattern的例子:
eg:url对应关系:
http://www.abc.com/article.html?act=test&id=123 -> http://m.abc.com/article.html?act=test&id=123
pattern:
http://www.abc.com/article\.html?act=([^&]+)&id=([^&]+) -> http://m.abc.com/article.html?act=${1}&id=${2}
8、PC存在分页对应移动页面生成pattern的例子:
http://www.a.com/1234-1.htm http://www.a.com/1234-2.htm ->http://m.a.com/1234.htm
pattern:
http://www.a.com/([0-9]+)-([0-9]+).htm -> http://m.a.com/${1}.htm
移动落地页检测工具是由百度搜索资源平台推出的,检测移动落地页是否符合《百度APP移动搜索落地页体验白皮书5.0》规范的工具。
移动落地页检测工具主要分为站点检测和URL校验两个功能。站点检测可对移动站点进行检测,URL校验是针对提交的URL页面检测。
本工具提供网站或URL重要问题反馈,但不是唯一问题,站点仍需全站自查。
第一步:登录百度搜索资源平台-搜索服务-优化与维护-移动落地页检测
第二步:如站点未在平台验证,需先验证站点后,才能使用落地页检测工具(站点验证图文详解)
第三步:移动落地页检测工具包括两个功能:站点检测与URL校验;建议站点先使用站点检测功能,整改后再使用URL校验功能。
站点检测可整体检测移动站点是否符合《移动落地页体验白皮书5.0》,并抽样反馈网站主要问题;网站也可使用URL检测方式,单独检查页面情况
第四步:站点参考问题反馈进行整改,整改完成后,滤镜问题将2周后自动恢复
① 站点检测功能查询结果天级更新。
② URL校验功能查询结果实时更新,每个账号每天限使用5次。
③ 建议站点先使用站点检测功能,整改后再使用URL校验功能。
④ 若站点内容已被滤镜,站点按照《移动落地页体验白皮书5.0》规范整改后,滤镜问题两周自动恢复。
⑤ 若工具检测反馈问题与站点情况不一致,请在反馈中心-网站支持-优化与维护进行反馈。
移动落地页检测工具是由百度搜索资源平台推出的,检测移动落地页是否符合《百度APP移动搜索落地页体验白皮书5.0》规范的工具。
移动落地页检测工具主要分为站点检测和URL校验两个功能。站点检测可对移动站点进行检测,URL校验是针对提交的URL页面检测。
本工具提供网站或URL重要问题反馈,但不是唯一问题,站点仍需全站自查。
第一步:登录百度搜索资源平台-搜索服务-优化与维护-移动落地页检测
第二步:如站点未在平台验证,需先验证站点后,才能使用落地页检测工具(站点验证图文详解)
第三步:移动落地页检测工具包括两个功能:站点检测与URL校验;建议站点先使用站点检测功能,整改后再使用URL校验功能。
站点检测可整体检测移动站点是否符合《移动落地页体验白皮书5.0》,并抽样反馈网站主要问题;网站也可使用URL检测方式,单独检查页面情况
第四步:站点参考问题反馈进行整改,整改完成后,滤镜问题将2周后自动恢复
① 站点检测功能查询结果天级更新。
② URL校验功能查询结果实时更新,每个账号每天限使用5次。
③ 建议站点先使用站点检测功能,整改后再使用URL校验功能。
④ 若站点内容已被滤镜,站点按照《移动落地页体验白皮书5.0》规范整改后,滤镜问题两周自动恢复。
⑤ 若工具检测反馈问题与站点情况不一致,请在反馈中心-网站支持-优化与维护进行反馈。
根据策略进行筛选,不保证完全采用。
什么是站点Logo?站点Logo是在百度搜索网站名称时,出现在网站名称下方的Logo标识,有利于增强站点曝光,更好地吸引搜索用户。PC端和移动端的展现示例如下。
开发者只需将站点与小程序相关联,并正确提交至少一条适配规则,即可优先获得站点Logo权限。
如果开发者尚未开通小程序,且在站点Logo界面有“一键创建并关联小程序”字样,点击即可一键创建并关联小程序,然后便可以参考《配置 URL 适配规则》提交适配规则,将H5资源替换为小程序资源。
如果开发者尚未开通小程序,且在站点Logo界面没有“一键创建并关联小程序”字样,可在智能小程序开发者平台参考《智能小程序注册指导文档》创建发布小程序,然后参考《关联 H5 站点》关联站点,最后提交适配规则,将H5资源替换为小程序资源,可参考《配置 URL 适配规则》。
如果开发者已开通小程序,可直接在智能小程序开发者平台关联H5站点并提交适配规则,可分别参考《关联 H5 站点》《配置 URL 适配规则》。
特别提醒的是,一个小程序只能为一个站点带来权益,请开发者合理设置关联,确保小程序与H5站点的稳定关联状态,以便权益正常使用、适配正常生效。
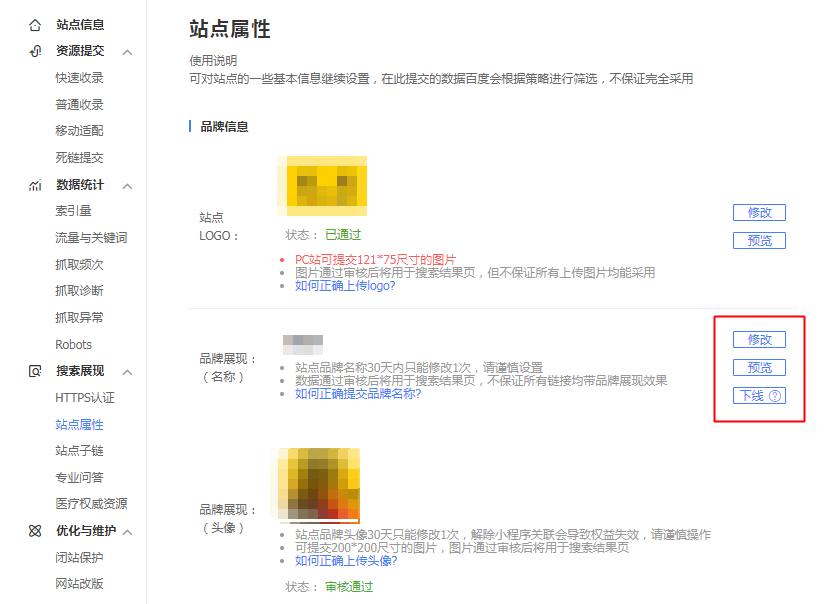
如何设置站点Logo?开发者可以通过“搜索资源平台-搜索服务-搜索展现-站点属性”设置站点Logo。
PC端与移动端的Logo图片尺寸要求不同,PC端为121*75,移动端为200*133,审核规范详见《【官方说明】站点属性(Logo)审核原则》。
在搜索结果页中,标题及摘要下方展现的,内容来源站点的头像与名称,叫作站点品牌展现。
相比只展示一串网站地址的方式,品牌展现更直观地体现了内容来源,加强了搜索用户对内容来源的信任度、对站点品牌的记忆度。
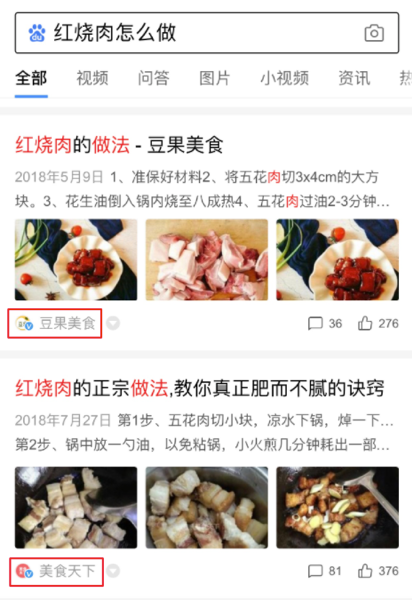
开发者将站点与小程序相关联,提交适配规则,顺利将一定数量的H5资源替换为小程序资源,使小程序在百度搜索中获得一定的分发与展现,就能优先获得品牌展现权益。
如果开发者尚未开通小程序,且在品牌展现界面有“一键创建并关联小程序”字样,点击即可一键创建并关联小程序,然后便可以参考《配置 URL 适配规则》提交适配规则,将H5资源替换为小程序资源。
如果开发者尚未开通小程序,且在品牌展现界面没有“一键创建并关联小程序”字样,可在智能小程序开发者平台参考《智能小程序注册指导文档》创建发布小程序,然后参考《关联 H5 站点》关联站点,最后提交适配规则,将H5资源替换为小程序资源,可参考《配置 URL 适配规则》。
如果开发者已开通小程序,可直接在智能小程序开发者平台关联H5站点并提交适配规则,可分别参考《关联 H5 站点》《配置 URL 适配规则》。
特别提醒的是,一个小程序只能为一个站点带来权益,请开发者合理设置关联,确保小程序与H5站点的稳定关联状态,以便权益正常使用、适配正常生效。如果站点与小程序的关联关系不在了,品牌展现权益也将失效。
如何设置站点品牌展现?开发者可以通过“搜索资源平台-搜索服务-搜索展现-站点属性”来设置站点名称与站点头像。
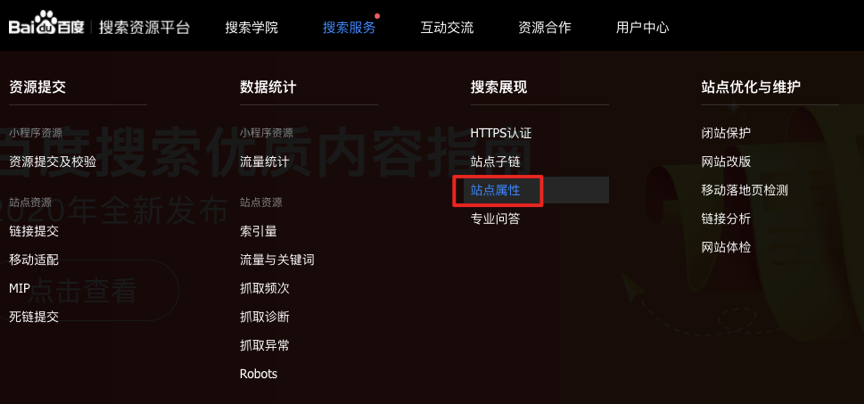
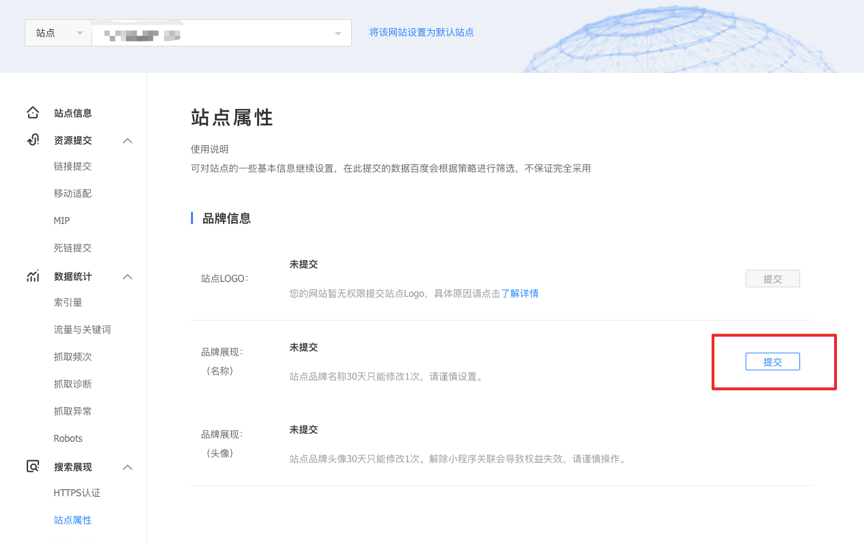
根据界面提示提交品牌名称与品牌头像,需满足名称与头像规范,提交后3个工作日内将反馈审核结果。开发者可参考《站点品牌展现名称及头像设置要求》进行设置,提高审核通过率。
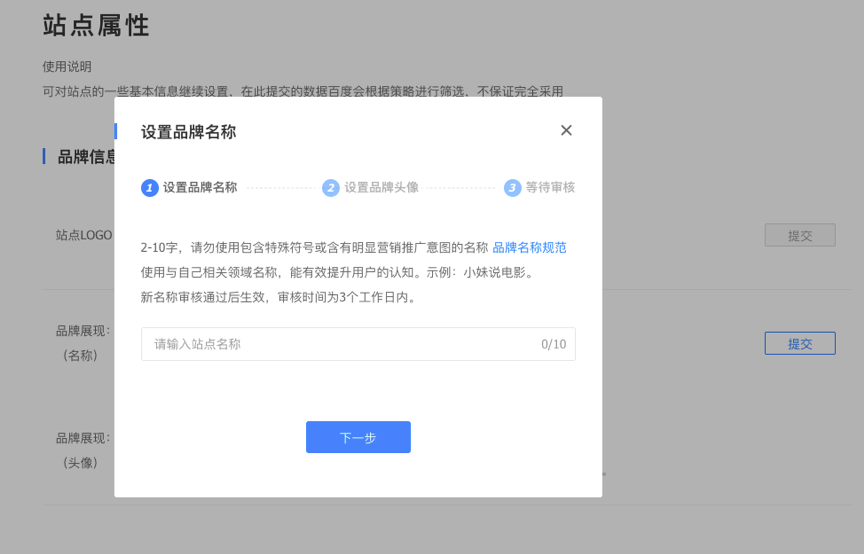
审核通过后,开发者可以在站点属性中进行修改、预览、下线等操作,30天内只可修改一次,请谨慎设置。
站点关联主体是移动资源进入搜索的一个必要环节。
站点关联主体以及主体认证能够更好的验证站点的真实性,相较于ICP备案存在代备案、过期等问题,站点关联主体更可靠,能够更好的保障大家的权益。
站点关联主体,是由站点的拥有者将名下站点关联到对应主体下的操作,拥有者可根据自身情况和需求,将站点关联到个人主体或非个人主体上。
PS:站点关联主体,不影响当前网站的排名、流量等。
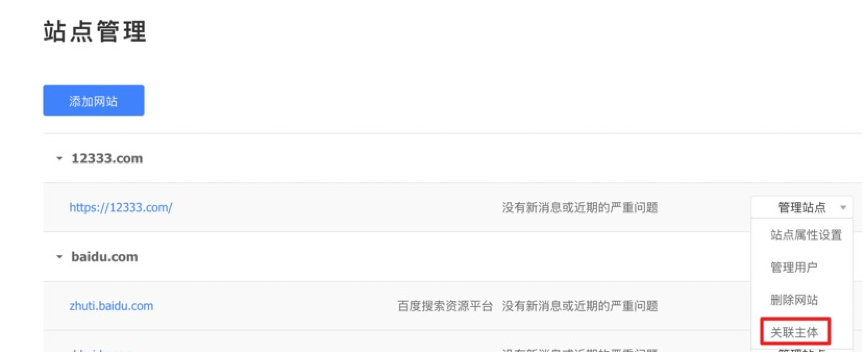
①登录站点对应的拥有者搜索资源平台账号,点击用户中心,选择站点管理。
②如果该站点已关联主体,会显示主体信息;若未关联主体,会显示未关联,可点击关联主体进入关联流程。
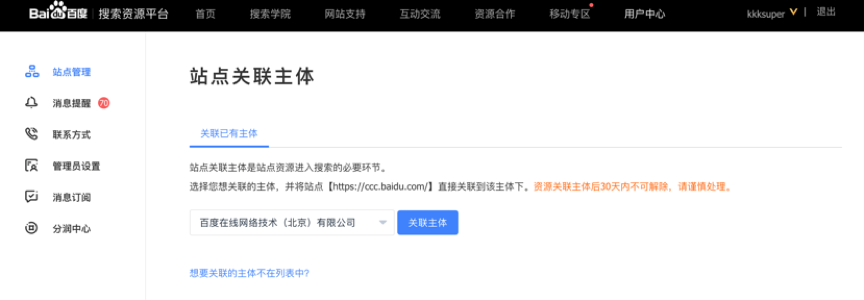
③在跳转的新页面中,从下拉框选择想要绑定的主体,您百度账号下已经存在关联了站点的主体,那么关联时这些主体可供选择和快捷关联。
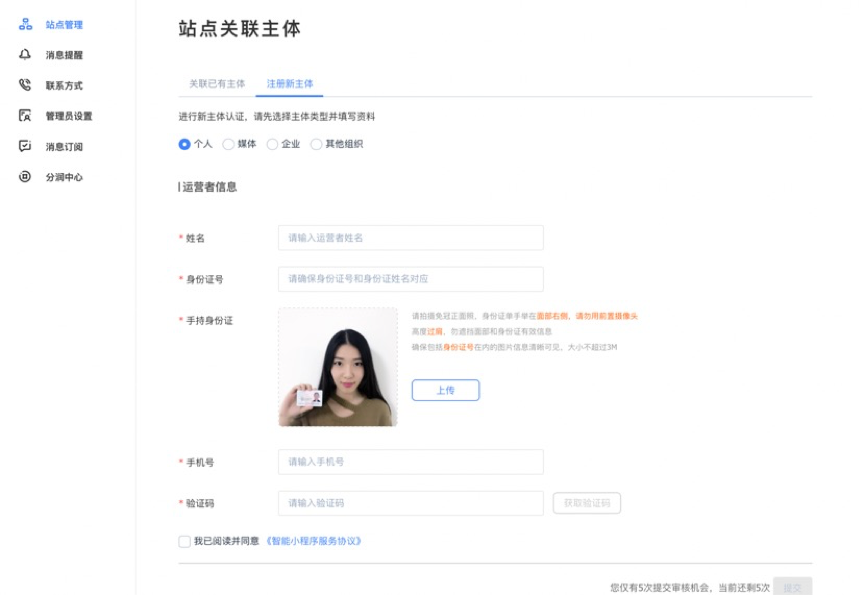
④如果您的百度账号未注册主体,可以以您的身份创建新主体(区分为个人主体、非个人主体)。个人开发者可以创建个人主体(填写本人身份证和真实姓名);非个人开发者,可创建对公主体(企业、组织机构等);
⑤绑定完成后,可在站点属性管理中查看自己已关联的主体信息,并进行操作。
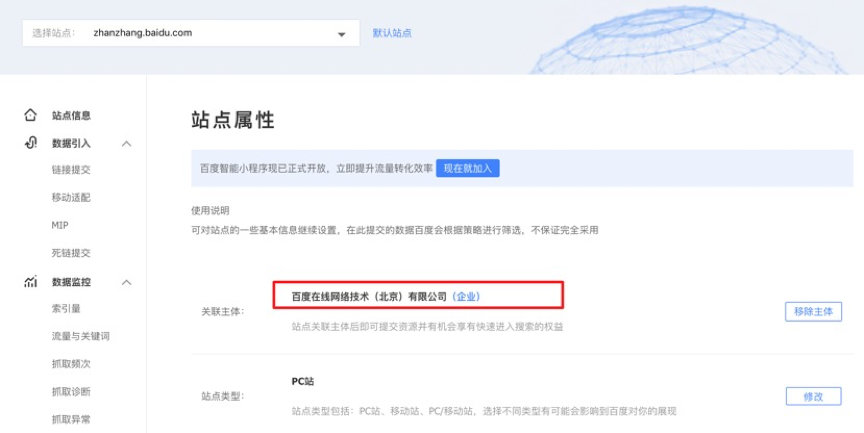
注意事项:站点关联主体,7天内不可解除,请谨慎绑定。
| 欢迎光临 中文搜索引擎指南网 (http://sowang.com/bbs/) | Powered by Discuz! X3.2 |