腾讯科技讯(Kathy)北京时间2月16日消息,据国外媒体报道,知名科技博客TechCrunch作者贾森·金凯德(Jason Kincaid)发表文章,讲述了他与谷歌语音技术负责人迈克·科恩(Mike Cohen)最近进行的一次谈话,内容涉及谷歌大力投入语音技术的原因及发展前景。
转播到腾讯微博
![]()
谷歌语音技术负责人迈克·科恩(Mike Cohen)(腾讯科技配图)
以下为全文摘要:
尽管智能手机应用程序花样翻新,层出不穷,但是如果你拿出手机,说一声“寻找到科技馆的道路”,谷歌就会立即照做的话,你仍然会感到这个情景有点不太寻常。语音技术通过iPhone应用程序,以及与Android的深度整合,正在变得日益普遍,而这实际上仅仅是一个开始。
回顾过去
在讨论现在的状况之前,我们先来回顾一下科恩过去的经历,也可以说这是在回顾语音技术的历史,因为虽然科恩从2004年开始一直在谷歌工作,但他自80年代初在斯坦福研究院做研究时起,就站在语音和技术的交汇之处,至今已经几十年了。
科恩说,在20世纪70年代语音工作有两大阵营:语言学家和工程师。语言学家强调规则——他们会找出语法和发音上的各种趋势,以及每一个音素如何与其他音素互动。工程师们则采用了不同的方法:他们的目标不是试图以人工方式精心确定每个规则,而是构建复杂的统计模型,当有更多的语音数据输入到这些模型中时,它们就会得以改进。
到了70年代末和80年代初,当科恩开始在斯坦福研究院做研究时,工程师们正处于领先位置,但是存在着这样一个问题:统计模型的改进已经开始形成渐近线。科恩解释说,因为这些模型总是相同的,向它们输入更多的数据终究会出现报酬递减(例如他们的模型不善于识别发音在多大程度上取决于哪些词被说出,又在多大程度上取决于上下文是什么)。工程师们需要找到一种方式来建立更好的模型,所以他们终于开始与语言学家们合作,造就了另一波研究热潮。
到90年代初,语音技术已经获得了长足的发展,研究人员创建了航空旅游信息系统(ATIS,Air Travel Information System,用户可以走到一个终端,说“告诉我从波士顿出发的航班”,计算机就会显示相关数据。该系统可以识别这些命令无数种的变化,因此你不必记住某些关键字)。在Windows 95面市时就有了ATIS这样的系统,这让人觉得有些不可思议。
在ATIS获得成功的基础上,科恩认为这项技术已经做好了商业应用的准备,所以他和三个联合创始人创办了Nuance公司,为需要处理大量呼入电话的大公司建立自动电话系统(电话公司的客户服务系统就是一个例子)。
科恩继续寻找改善Nuance语音识别软件的方法(鉴于他曾是一位研究者,这也就不足为奇了)。而且事实证明,海量的呼入录音比他在斯坦福研究院做研究时获得的数据更加有用,因为有些东西无法在实验室环境中重现,比如背景中的狗叫声,孩子的哭声等等,而这些声音会出现在呼入的电话中,所以Nuance面临着语音分析的重大新挑战。
但这里有一个很大的问题:尽管Nuance的技术正在处理大量数据,Nuance公司还是必须向它的每个企业客户提出请求,以便获得这些数据用于研究目的。这样做对企业有好处,因为它们能从技术改进中获益,但一些企业仍然对此持谨慎态度。这最终导致科恩进入了谷歌。
GOOG-411项目
在2004年前,谷歌基本上没有语音技术,但是科恩看到了机会。即使在那个时候,手机将对未来技术产生巨大影响的迹象就很明显。而且,由于谷歌直接面对最终用户,它收到的任何语音数据都可以方便地用于研究目的。于是科恩进入谷歌,着手开展GOOG-411项目,后来它成为谷歌的免费411语音服务。
这项服务在2007年推出,它提供了一个简单方便的功能集:你给它打电话询问一些基本信息,比如一个企业的电话号码,它就会马上为你提供相关信息,而且是免费的。科恩说,推出GOOG-411的主要原因就是“它有用”,但它还有一个重要的副作用:谷歌从此开始建立一个庞大的语音数据库。还记得前面讨论过的数据模型吗?谷歌语音系统在概念上与之类似,但是规模大得多。
GOOG-411项目在十月份取消了,但这时谷歌已经有了更多的语音数据输入方式,包括在Android上到处可见的麦克风按钮,以及Google Mobile的iPhone应用程序。而且谷歌可以查看基于文本的搜索查询词条,确定一个词后面出现得最频繁的是哪个词。这一切都意味着谷歌可以相对较快地改进其语言模型。
科恩说,如今谷歌使用2300亿个搜索查询词条来“培训”其语音识别功能所使用的语言模型。为了形象地说明数据量有多大,科恩说,如果只用一个CPU,这个“培训”需要70年时间才能完成。
这项技术现在已经用在谷歌的多种产品中。YouTube自动为数百万视频添加了字幕。谷歌语音服务尝试将呼入的语音邮件转录成文字(产生了一些非常滑稽的结果)。语音搜索将在移动设备上发挥更大的作用,所以,如果在不太遥远的将来,你看到配有媒体中心的车辆在运行Android,请不要感到惊讶,它们肯定带有语音功能。
科恩很高兴地谈起谷歌在声音技术上做出的努力,但他没有透露统计数据,即将发布的功能,也没有做出预测。科恩承认,谷歌语音搜索的量波动很大,取决于是否有新的带有语音功能的服务推出,以及是否报刊最近进行了报道。
当我问他,多久之后语音搜索将变得非常准确,以至于我们可以将它视为理所当然(指不需要再检查文字的拼写错误),虽然他说了类似于“五年”这样话(对于研究工作而言,这相当于是说“我不知道”),但他不愿意谈及具体计划。
我也问过他,对苹果在语音技术方面采取的行动有什么想法(苹果去年收购了以语音搜索技术为主的公司Siri,很明显苹果想把将语音技术纳入到iOS中),科恩同样也没有这个问题上说多少(虽然这并不令人感到惊讶)。他只是说,谷歌已经推出了一个产品,因此拥有数据量大的天然优势,但这个问题的答案最终将归结于苹果开发了什么产品以及它与谁合作。
不过,虽然科恩没有谈及具体细节,他却讲到了谷歌语音技术的长远目标:让语音输入变得无处不在。 “就像你可以在很多地方用键盘输入文本,你也应该可以在很多地方使用语音输入。”而准确性是其中的一个要点 “它需要极为‘接近完美’,人们选择使用语音输入不在于它的表现,而在于最终用户的喜好。” | 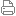





 IP卡
IP卡 狗仔卡
狗仔卡
 发表于 2011-2-16 23:51:28
发表于 2011-2-16 23:51:28
 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡